但是DQN在斗地主的应用中同样存在动作空间过大的问题,使用DQN会导致结果估计和机器运算时间过长;而且斗地主的奖励稀疏(sparse reward)问题会导致DQN的收敛速度大大降低。因此DQN也不适用于斗地主游戏。
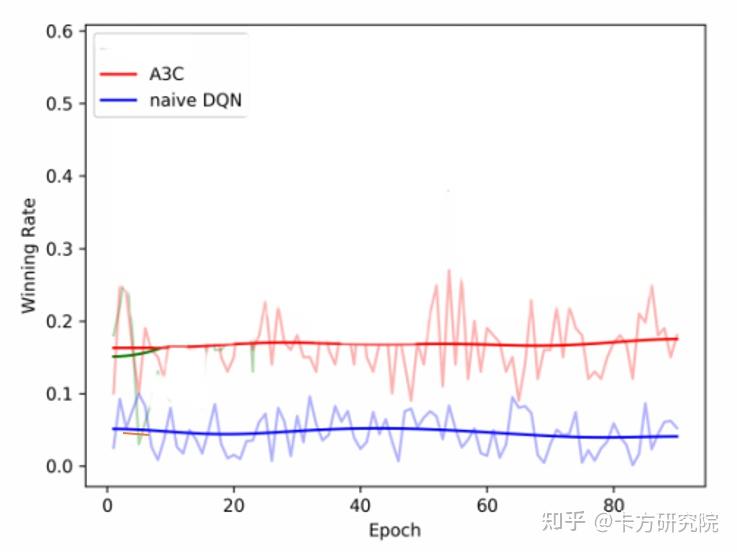
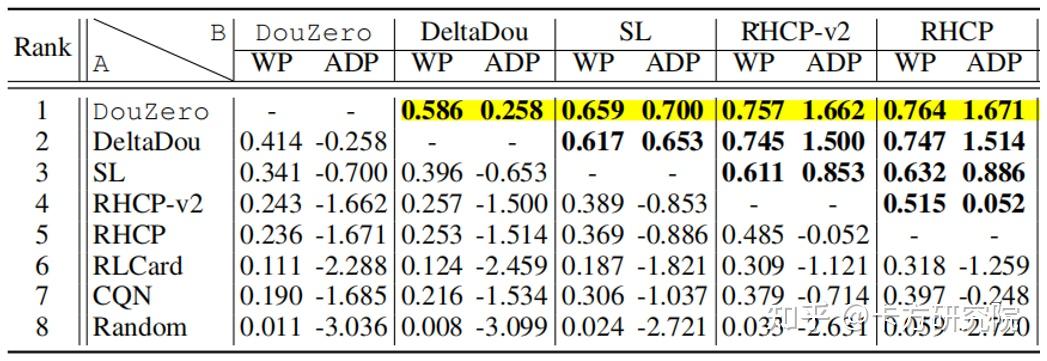
You(2019)将DQN、A3C,与RHCP(递归拆牌Recursive Hand Cards Partitioning)进行对比,发现DQN、A3C的胜率仅在20%以下(图表5)。
此外,由于A3C算法需要在价值函数优化求解的过程中,不断更新未来动作的概率。而在斗地主游戏中,牌池中剩余的牌和已经打出的牌关系很大,要严格准确概括牌组隐藏的出牌概率难度很大,因此A3C算法在斗地主中的适用性也不高。
图表 5 A3C、DQN与非机器学习算法在斗地主游戏中的胜率比较
<hr/>III.DeltaDou——AI崛起
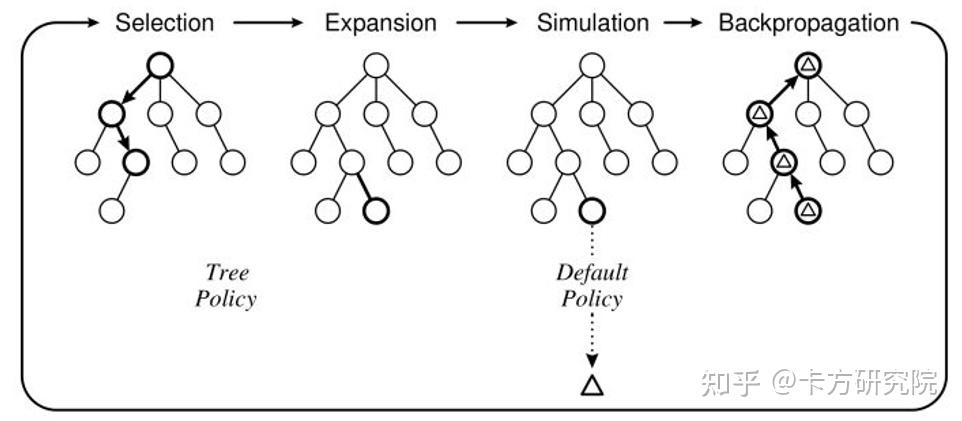
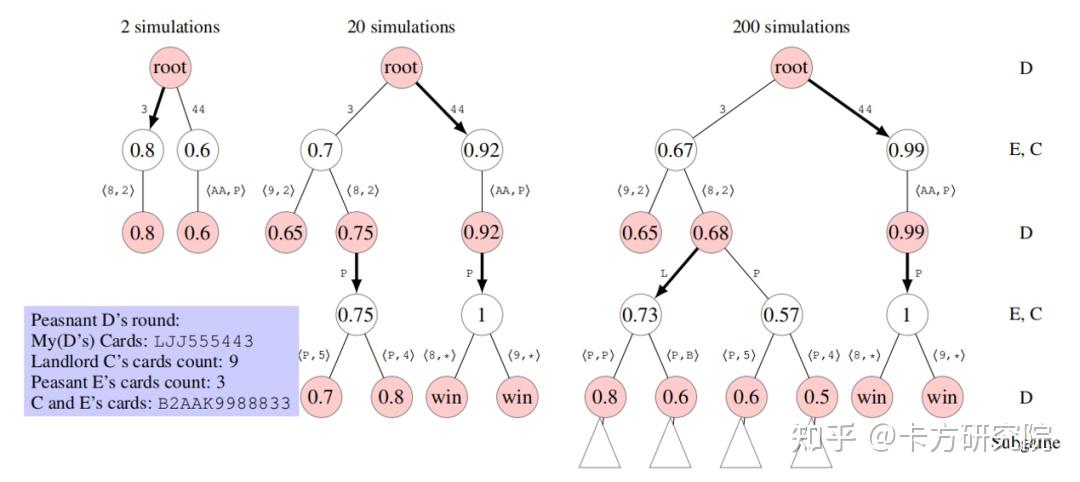
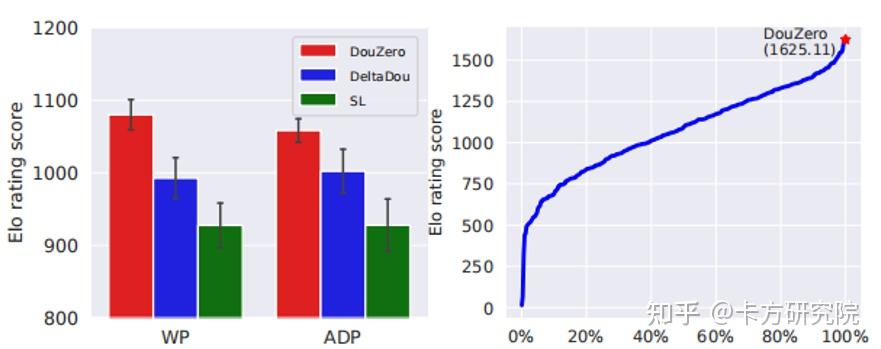
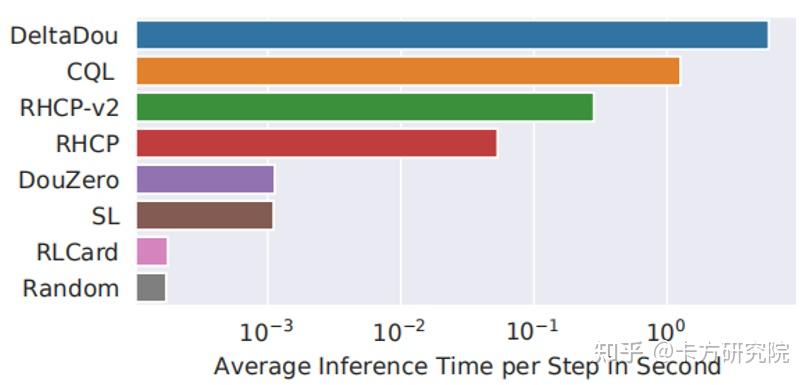
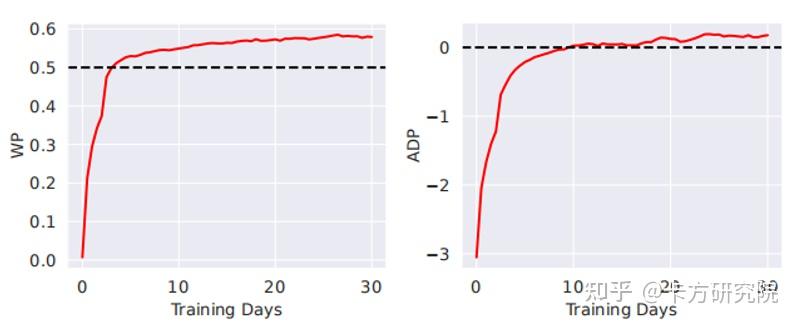
Jiang(2019)提出的DeltaDou是第一个可以和顶尖真人斗地主玩家媲美的AI。为了解决不完全信息博弈问题,他结合了寻找纳什均衡和长期收益最大化两种思想,提出了虚拟博弈蒙特卡洛搜索树FPMCTS(Fictitious Play MCTS),并使用两种评分机制来评估算法效果。 a)虚拟博弈蒙特卡洛搜索树
[1] Martin Zinkevich. Regret Minimization in Games with Incomplete Information.2008
[2] Yang You. Combinational Q-Learning for Dou Di Zhu.2019
[3] Volodymyr Mnih. Human-level control through deep reinforcement learning.2015
[4] Qiqi Jiang. DeltaDou: Expert-level Doudizhu AI through Self-play.2019
[5] Daochen Zha. DouZero: Mastering DouDizhu with Self-Play DeepReinforcement Learning.2021
[6] Suton, Barto. Reinforcement Learning:An Introduction.2018



 发表于 2022-9-20 15:23:52
发表于 2022-9-20 15:23:52