|
|
这次来讲一下快手ICML2021 斗地主这篇文章。
文章链接:
github链接
搜了下相关文章,已经有大佬讲解过,但总感觉有些细节没有讲完,这次详细阅读了下文章,试着从原理细节部分再分析下文章。当然,也可以结合下面文章一起阅读。
这个大佬好像还自己调用了douzero来帮自己斗地主,真强。
所以本文主要是从原理上来讲解,关于代码或者怎么应用,可以参看上面推文。
规则
关于斗地主的规则,玩法,这里就不详解,想必大家基本都会了哈,不会的话可以自行搜一下。
状态的编码
对于拿到手的牌,作者是这样编码的,如下图:

图1 状态编码
这里解释下,因为牌的种类就是3-10,J, Q, K , A, 2,小王,小王总共15种。(除了大小王分花色,其他的无论是方块或者红桃对斗地主来说其实都一样);然后每一种牌最多只有四张。(大王小王各一张);所以这里使用了一个15×4的矩阵来表示就足够了。
例如上图的第一列,表示的是3,因为为两张3的牌,所以从最下面的标为1,再往上标一个1.以此类推,对于10,因为有四张,所以都是1;因为没有A,所以A的位置都是0.
再给出一两个编码例子:
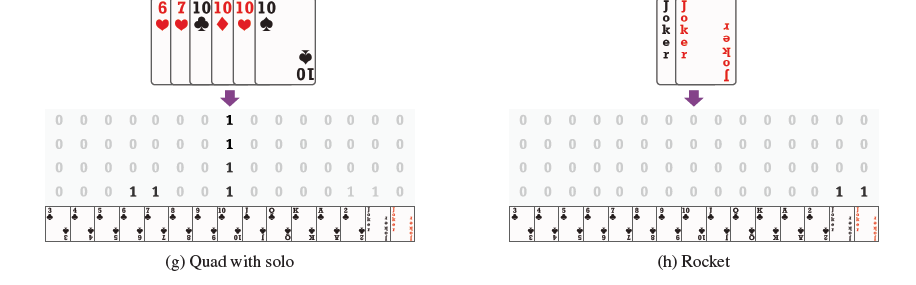
图2 编码2
其实大家如果之前看过微软的suphx麻将的论文,就会发现这里跟之前suphx的编码麻将的基本一样了。这里放一张图感受下:
图3 suphx 编码
这些不详细说了,有兴趣的话可以看下suphx的论文。或者看下下面链接或者b站讲解。
扯远了,回来。
当然,作者定义的state不止这些,在解释其他state定义之前,这里先解释下action空间,(因为定义时候采用了action)。
action
对于斗地主,其动作空间是离散的,但是有多大呢?大家可以先思考下,下面给出了答案:
The size of the action space of DouDizhu is 27 472, which is much larger than Mahjong (100).
没看错,这里27472 应该就是遍历有所有的可能,作者给出了下表的统计:
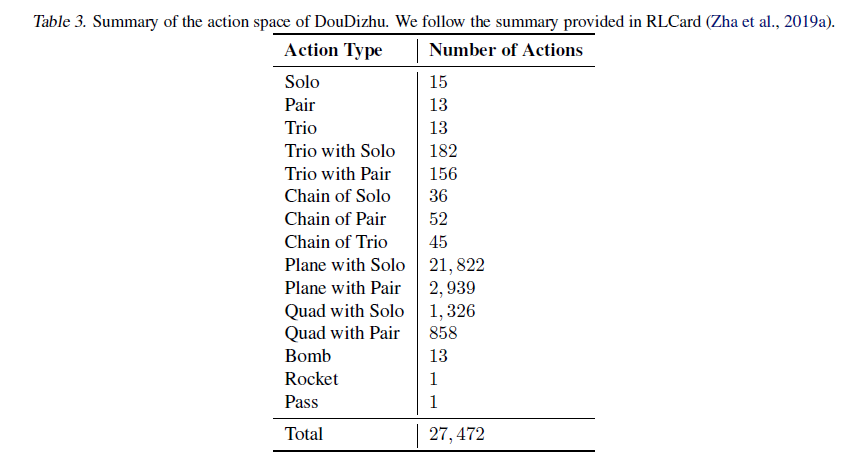
图4 动作种类
关于上图的翻译,大家可以结合自己的斗地主经验翻译一下,大概的意思就是:
如果出单张的话:就有15种,
出对子的:就有13种(因为大王小王除外);三张类似等等。
这里给出了一张近似的中文表可以对应一下:
图5 中文意思
27472什么概念,大家应该懂,如果直接建模一个Q网络,然后输出27472个 Q\left( s,a \right) ,一般是训练不出来的。并且对于你拿到的牌,有很多的动作是非法的。例如下图:
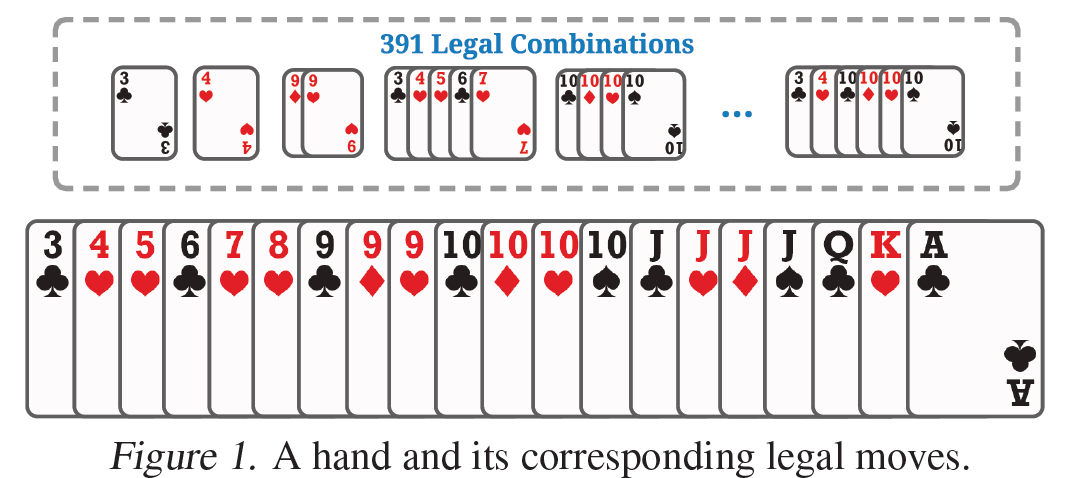
图6 手中的牌和此刻的合法动作
对于上图拿到的牌,最多也就是391个出牌选择。至于391种怎么算出来,笔者觉得遍历应该是可以算出来的,总之,这里要明确的一点就是,对于你手中的牌,是有现成的方法可以列出你此刻的出牌所有种类。这个在后面需要用到,这里mark一下。
所以,对于27472这多大的空间,作者们的解决方案是,类似于DDPG,对于一个Q网络,输入的不止是s,他们把a也输进去,然后直接输出一个值 Q\left( s,a \right) .
到这里就可以回到state定义的问题:
- 首先,对于你此刻手中的牌,可以编码为一个15×4,然后因为小王,大王本来最多就只有各一张,其上面对应的各自的三个位置一定为0,把15*4 拉成一维,同时去掉6个0,就剩下54维vector。关于作者为什么要强行拉成一维度而不是直接对15×4使用CNN,应该就是fc计算和内存都比较友好,然后也能训练出不错模型吧。
- 同样对于你手中的牌,你都可以根据现成的方法(至于这个方法的遍历逻辑,代码中应该有,大家可以去代码里面看看)列出你此刻所有的出牌方案,例如上图,有391中方法,对于每一种出牌方案,都可以采用相同的编码方式,变成一个54维的vector。例如下图给出了一些action的编码。
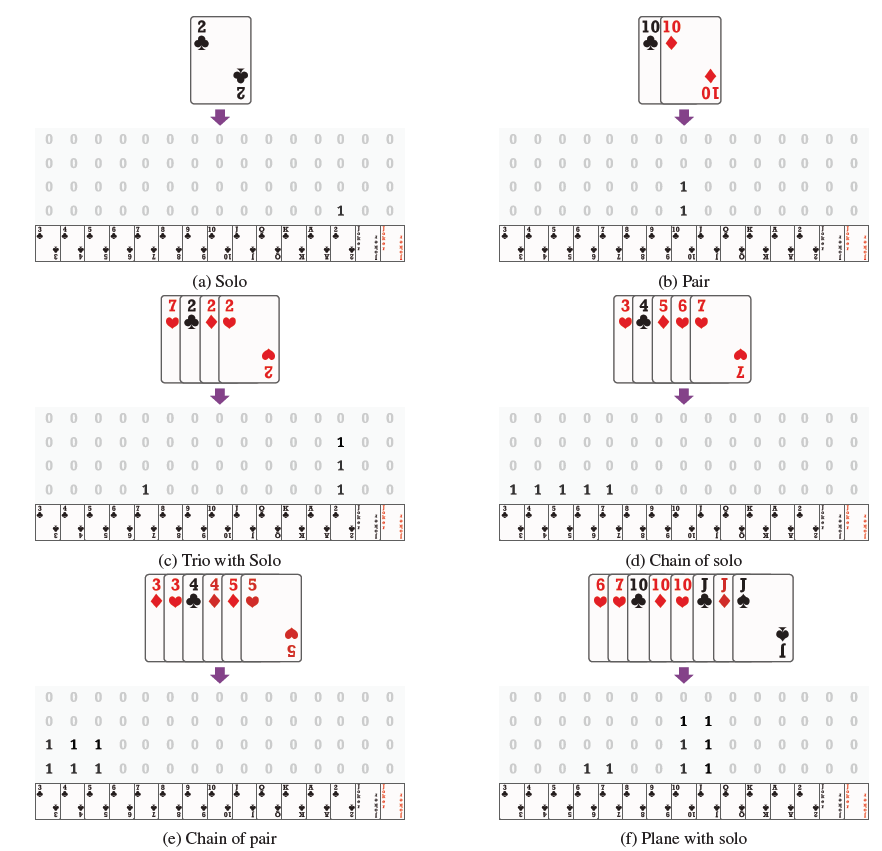
图7 动作编码
在算 Q(s,a) 时候,应该可以列出中319中 (s,a) 组合,一个batch全部forward得到所有的Q值,然后再通过 \epsilon-greedy 选择动作吧。论文中似乎没有很详细的写,但笔者觉得应该就是这样的。
说完动作的编码,当然还有其他的一些编写信息,这里先给张图再详细介绍下:
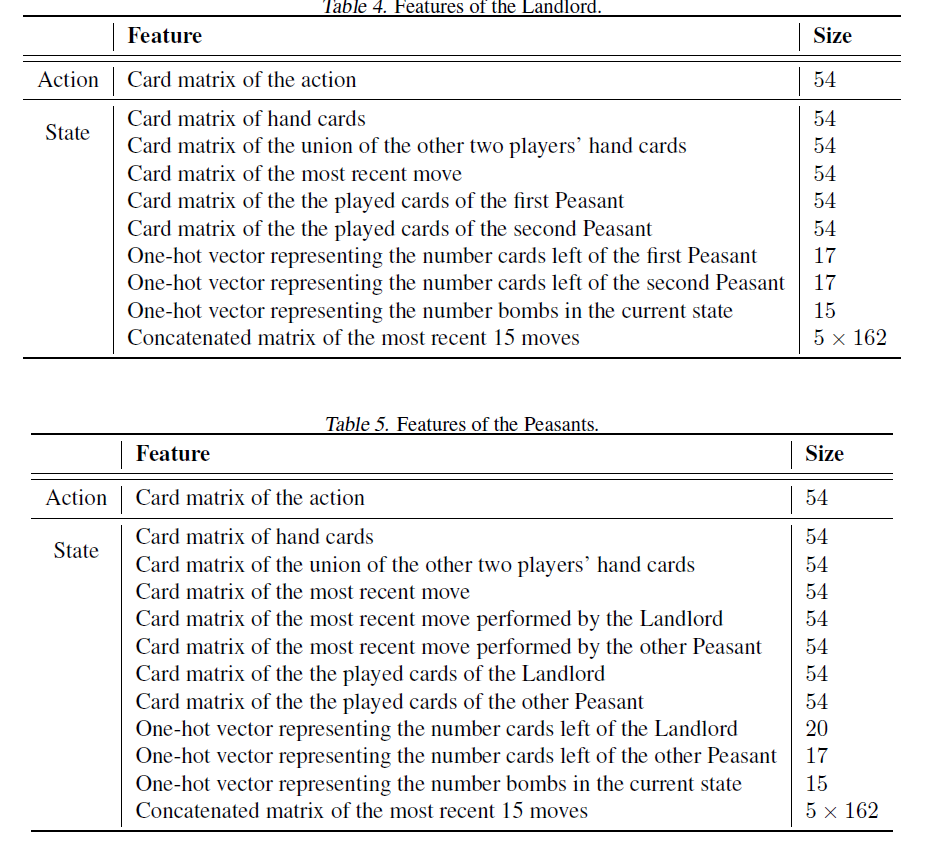
图8 农民和地主的状态定义
这里详细介绍下:
作者针对三个玩家建模了三个模型,分别是第一个农民,第二个农民和地主。两个农民的模型结构,状态完全一样,但是各自使用自己的模型。地主的牌多三张,与农民的状态稍微有一点不一样,但基本相同。这里详细介绍下上表中地主的所有状态。
- Action Card matrix of the action 54,这个上面已经解释过了
- Card matrix of hand cards。就是你手中现在的牌,上面也解释过了
- Card matrix of the union of the other two players’hand cards。除了你自己手上的牌,还有打过的牌,就可以知道其他两个玩家的手上牌的总和,从而也可以使用一个54维向量来表示。
- Card matrix of the most recent move 这个应该是自己的最近一次出牌?
- Card matrix of the the played cards of the first Peasant。第一农民的最近一次出牌?
- Card matrix of the the played cards of the second Peasant。第二农民的最近一次出牌?
- One-hot vector representing the number cards left of the first Peasant,第一个农民此刻手中还有多少牌,农民最多有17张牌,所以是一个17维one-hot向量。
- One-hot vector representing the number cards left of the second Peasant。第二个农民此刻手中还有多少牌。
- One-hot vector representing the number bombs in the current state。此刻还有哪些可能存在的炸弹。
- Concatenated matrix of the most recent 15 moves ;5 * 162。过去5轮出牌的情况,每一轮三个玩家各出一次牌。54*3=162.所以是一个5 * 162。这里使用了LSTM。(有点疑惑是这里使用过去的出牌,包含了4-6的编码,那么4-6是否就没有必要,还是4-6定义的是其他?)
同样对于农民的状态,也是类似。这里不重复了。所以作者最后使用的网络结构如下,后面都是MLP,6层。
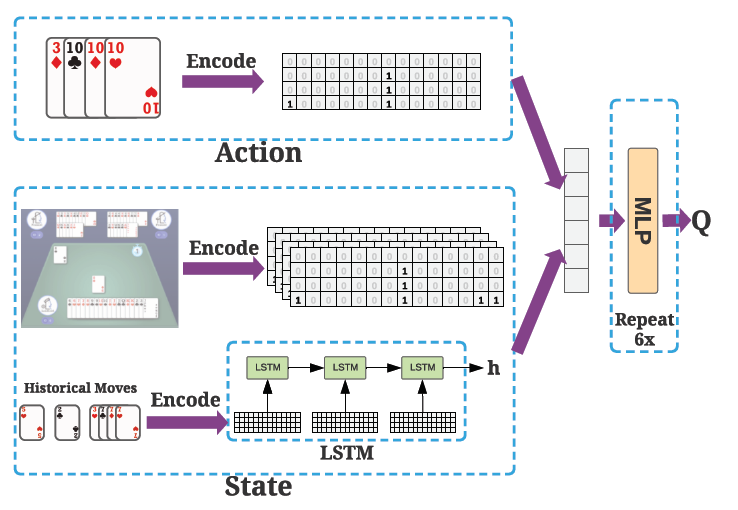
图8 网络结果
rewards
奖励的定义有两种方案,作者们也训练了两个模型
- WP (Winning Percentage):每一局按照胜负来,前面的step reward都是0;最后胜利的是1.失败是-1
- ADP (Average Difference in Points):按照分数来,应该就是类似欢乐豆,每次赢的分数不一样,例如有炸弹,double。同样前面的step reward都是0;最后胜利的是赢得的分数.失败是输掉的分数。
训练和算法选择
作者使用的是Deep Monte-Carlo,也就是MC的方法,注意这是并不是MCTS,具体的做法就是:

图9 MC方法
这里使用MC可能是因为rewards 稀疏的问题,当然作者也有对比了其他AC等算法,发现并不work。所以使用MC。简要解释下上面的MC算法,这里的MC跟我们平时见到的MC似乎有点区别,传统的MC应该是

图10 Incremental Monte-Carlo Updates
可以参考下这文章
作者这里的MC基本就是类似于n-steps return了,只是这里的n得跑完一整个episode,对于斗地主来说就是打完这一局,因为奖励稀疏的问题,打完才会有一个reward,再回溯给到这个episode的每一对 (s,a) ,也就是下面这样计算了:

图11 奖励计算
文章种最后使用的 \gamma 为1。使用 \xi-greedy 在训练的时候增加探索。
并行训练
使用了多个Actors来采集数据,和一个Learner来训练,同时定时从learner拷贝新的模型参数过来给actor,有点类似于Ape-X的方式。
具体的算法流程如下:
对于Actor process

图12 actor process
其实这里有点不是很明白 buffer里的entries和size概念,感觉也应该直接理解为buffer size。也应该就是存储的空间之类。使用了三个模型,三个buffer,跑完一个esipode,就分别往三个buffer里面放东西。
对于learner:

图13 learner
结合这里,作者最后使用的M,S参数如下:

每一次learner采样数据的时候都会free the entries,所以actor中才会有Request and wait for an empty entry in B吧。按照这里的理解应该是每一笔数据只会被训练一次,然后就舍弃了。可能因为n-steps return 也不是很适合 off-policy,严格的话得加下IS之类,不能使用过久的策略的数据来训练吧。这里跟普通的DQN和replay buffer还是有点小不一样的。
他们使用了1台48cpu核+4个1080TI GPU的服务器。开了45个actors利用了3个GPU(这里的GPU应该是用来推理,类似了GA3C模式吧),然后另外一个GPU配给learner。使用了TorchBeast的框架。
其他
使用人类的数据,如果直接使用分类27472类别,还是比较难训练的,这里作者换了一种trick,我的理解就是:对于此刻手中的牌,遍历所有的出牌种类,如果是人类玩家的出牌方法,数据label就是1,不是的话就是0。所以就是二分类的问题。虽然会有数据不均衡的问题,但是也可以采用re-weight的方式来解决。具体的模型如下:
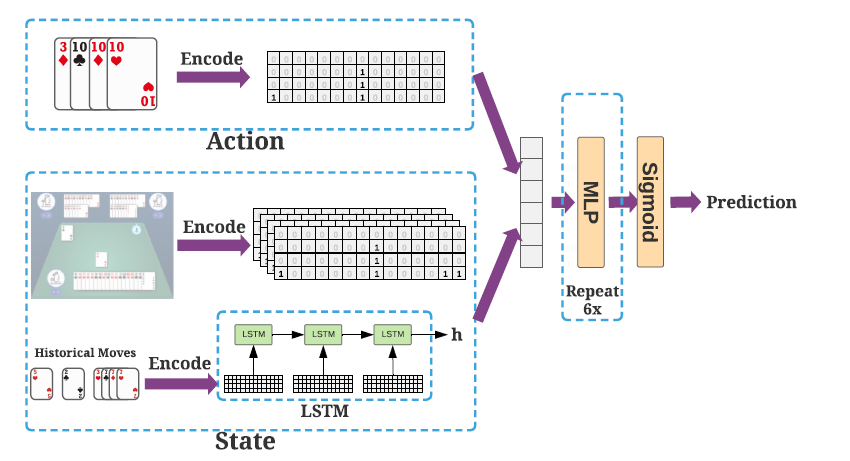
图14 SL模型
推理的时候,把所有的action种类输进去网络,挑概率最大的action出牌。
斗地主的会有一个抢地主的过程,这个过程应该可以独立上面的过程或者在训练的时候也加入进去。文章使用的抢地主模型也就是监督学习方法。
大概就是根据人类的数据,结合手中的牌,决定要不要抢地主。
大致定义的状态如下。这里不详细展开了。

图15 bidding 模型特征
因为这个模型训练得好的话只是锦上添花的作用,并不是雪中送炭。不用这个模型的话,训练self-play的时候大家轮着当地主也是可以训练。文章训练出牌模型的时候好像也没有加入这个模型。只是最后实验结果的时候加了下。
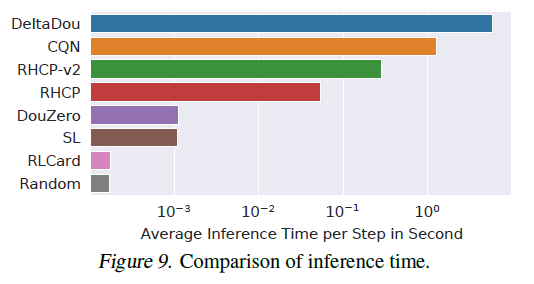
实验结果
作者的实验结果附录部分太多了。
这里简单列几点。
- 在北大的Botzone 这个leaderboard排名第一(总共344支队伍),作者好像也吐槽了leaderboard上的Elo-system分数和match组队的方式不是很稳定或者需要长时间才能稳定之类。
- 训练了30days,吊打其他baseline,结果如下图16:
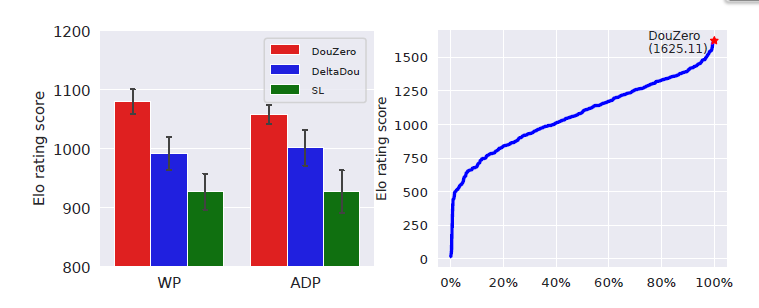
图16 结果1
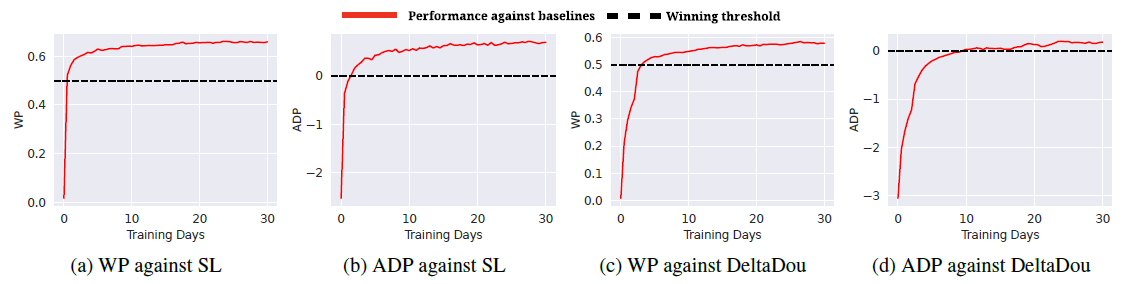
图16 WP和ADP的训练方法
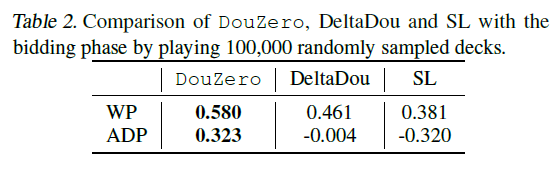
- 使用WP胜率的方式效果好一点。前者比较倾向于出炸弹,如果使用分数reward的话,可能不是很倾向于出炸弹。因为炸弹一出,分数double了,赢得多,输得也多。
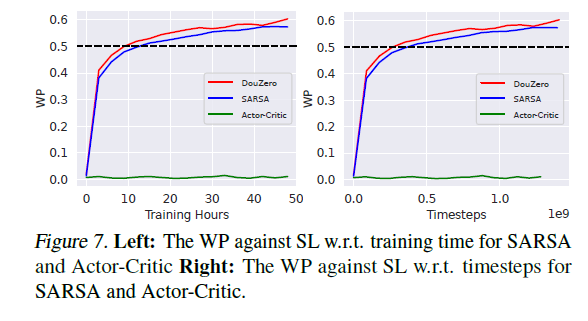
- actors越多,在前面50h时候训练速度可能会加快点,但如果都训练30days,估计性能持平。如下图17
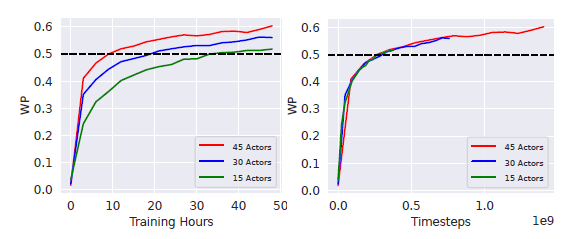
图17 训练时间or训练steps横坐标的比较
- 对比人类数据,学到后面,出牌套路跟人类越来越不一样
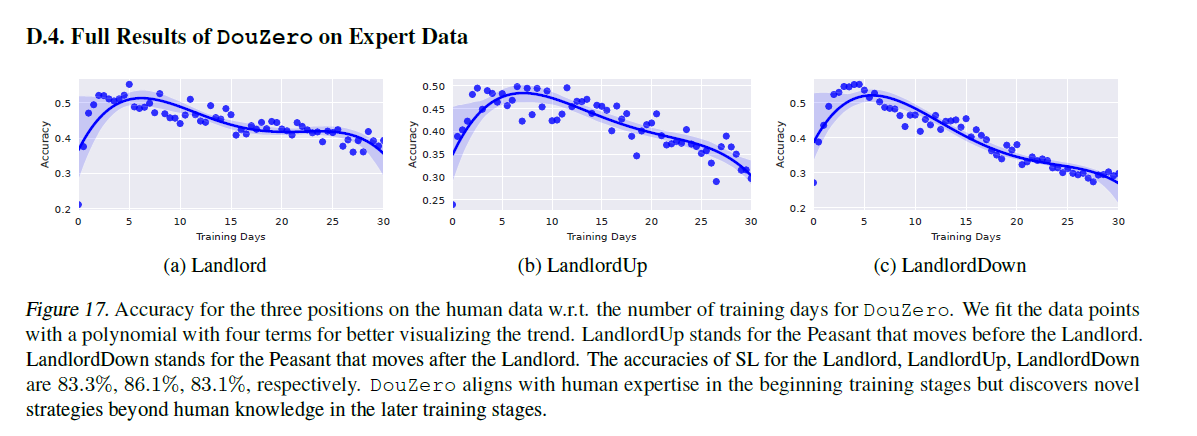
出牌套路跟人类的一致性
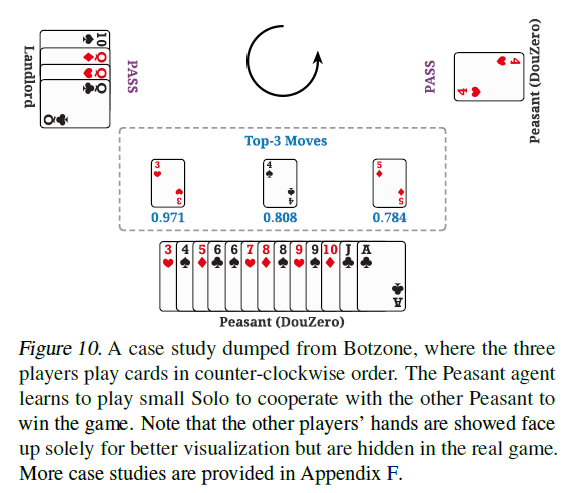
- 农民之间还是能学到一些合作,例如当对方只剩下一张牌的时候,会出一张小牌让下一位农民赢。例如: 当对方只剩下一张4的时候,我不知道对方的牌,只知道只剩下一张,出3的或者Q值为0.971,4的Q值为0.808之类。作者还给出其他一些例子,这里不列出了。
 |
|



 发表于 2022-9-23 12:52:24
发表于 2022-9-23 12:52:24